Voyager —— 使用基于 LLM 驱动的 Agent 探索 Minecraft
· 阅读需 17 分钟
官方网址:https://voyager.minedojo.org/
用基于 LLM 的 Agent,通过“提问→求解→技能池”循环来不断探索游戏内容。和 SOTA 比,建造物品的数量是 3.3 倍、探索范围是 2.3 倍、解锁关键科技结点的速度是 15.3 倍。

关键概念
系统整体逻辑循环如下:

- Automatic Curriculum: Curriculum Agent —— 提出目标
- Iterative Prompting Mechanism: Action Agent —— 实现目标
- Self-Verification: Critic Agent —— 检查是否完成目标
- Skill Library: Skill Manager —— 技能库
使用方式
from voyager import Voyager
azure_login = ...
openai_api_key = ...
voyager = Voyager(
azure_login=azure_login,
openai_api_key=openai_api_key,
)
# start lifelong learning
voyager.learn()
系统循环
https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/voyager.py
__init__: 定义上述 3 个 Agent (Action, Curriculum, Critic),1 个 Manager (Skill Manager)
# init agents
self.action_agent = ActionAgent(
model_name=action_agent_model_name, # gpt-4
...
)
self.curriculum_agent = CurriculumAgent(
model_name=curriculum_agent_model_name, # gpt-4
temperature=curriculum_agent_temperature,
qa_model_name=curriculum_agent_qa_model_name, # gpt-3.5-turbo
qa_temperature=curriculum_agent_qa_temperature,
...
)
self.critic_agent = CriticAgent(
model_name=critic_agent_model_name, # gpt-4
...
)
self.skill_manager = SkillManager(
model_name=skill_manager_model_name, # gpt-3.5-turbo
temperature=skill_manager_temperature,
retrieval_top_k=skill_manager_retrieval_top_k,
...
)
learn: 学习循环,提出任务 → 尝试完成任务 → 记录新技能
while True:
if self.recorder.iteration > self.max_iterations:
print("Iteration limit reached")
break
task, context = self.curriculum_agent.propose_next_task( # 提议下一个任务
events=self.last_events,
chest_observation=self.action_agent.render_chest_observation(),
max_retries=5,
)
...
try:
messages, reward, done, info = self.rollout( # 尝试完成任务
task=task,
context=context,
reset_env=reset_env,
)
except Exception as e:
...
if info["success"]:
self.skill_manager.add_new_skill(info) # 如果成功,则记录新技能
self.curriculum_agent.update_exploration_progress(info) # 更新探索进度
...
rollout: 完成任务,准备完毕后最多尝试执行 N=4 次reset: 准备工作- 使用 Skill Manager 获取与当前上下文匹配的技能信息,准备 Action Agent 的人设、提问等
step: 执行一次完成任务的尝试- 调用 Action Agent 背后的 LLM 得到 bot 的指令代码
- 尝试使用 MC 插件运行代码,解析结果
- 调用 Critic Agent 背后的 LLM 检查任务是否完成
- 使用 Skill Manager 更新与当前上下文匹配的技能信息,准备 Action Agent 的人设、提问等
def rollout(self, *, task, context, reset_env=True):
self.reset(task=task, context=context, reset_env=reset_env) # 准备工作:获取技能信息、准备 Action Agent 的人设、提问等
while True:
messages, reward, done, info = self.step() # 尝试一次
if done:
break
return messages, reward, done, info
def reset(self, task, context="", reset_env=True):
...
skills = self.skill_manager.retrieve_skills(query=self.context) # 获取相关技能
...
# 生成 Action Agent 所需的系统设定和提问消息
system_message = self.action_agent.render_system_message(skills=skills)
human_message = self.action_agent.render_human_message(
events=events, code="", task=self.task, context=context, critique=""
)
self.messages = [system_message, human_message]
...
return self.messages
def step(self):
...
ai_message = self.action_agent.llm(self.messages) # Action Agent 生成代码
...
self.conversations.append(
(self.messages[0].content, self.messages[1].content, ai_message.content)
)
parsed_result = self.action_agent.process_ai_message(message=ai_message) # 处理生成的 js 代码
success = False
if isinstance(parsed_result, dict):
code = parsed_result["program_code"] + "\n" + parsed_result["exec_code"]
events = self.env.step( # 运行处理好的 js 代码
code,
programs=self.skill_manager.programs,
)
...
success, critique = self.critic_agent.check_task_success( # 检查任务是否完成
...
)
if self.reset_placed_if_failed and not success:
...
# 根据当前上下文重新检索技能
new_skills = self.skill_manager.retrieve_skills(
query=self.context
+ "\n\n"
+ self.action_agent.summarize_chatlog(events) # 从代码运行结果中手动提取事件
)
# 更新 Action Agent 的系统设定和提问信息
system_message = self.action_agent.render_system_message(skills=new_skills)
human_message = self.action_agent.render_human_message(
events=events,
code=parsed_result["program_code"],
task=self.task,
context=self.context,
critique=critique,
)
self.last_events = copy.deepcopy(events)
self.messages = [system_message, human_message]
else:
...
...
done = ( # 超过重试次数,算失败
self.action_agent_rollout_num_iter >= self.action_agent_task_max_retries
or success
)
...
return self.messages, 0, done, info
Curriculum Agent
__init__: 定义 LLM, warm_up schedule, qa_cache vectordb 等
...
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
...
from langchain.vectorstores import Chroma
class CurriculumAgent:
def __init__(
self,
...
):
self.llm = ChatOpenAI(
model_name=model_name,
temperature=temperature,
request_timeout=request_timout,
)
self.qa_llm = ChatOpenAI(
model_name=qa_model_name,
temperature=qa_temperature,
request_timeout=request_timout,
)
...
# vectordb for qa cache
self.qa_cache_questions_vectordb = Chroma(
collection_name="qa_cache_questions_vectordb",
embedding_function=OpenAIEmbeddings(),
persist_directory=f"{ckpt_dir}/curriculum/vectordb",
)
...
# if warm up not defined, initialize it as a dict, else, initialize all the missing value as a default value
if not warm_up:
warm_up = self.default_warmup
self.warm_up = {}
...
propose_next_task: 提议下个任务- 硬编码:首个任务必须是砍树
- 硬编码:当身上物品太多时,尝试造储物箱,并存储身上的物品
- 否则,调用 LLM 来决定下个任务是什么
def propose_next_task(self, *, events, chest_observation, max_retries=5):
if self.progress == 0 and self.mode == "auto": # 硬编码,首个任务是砍树
task = "Mine 1 wood log"
...
return task, context
# hard code task when inventory is almost full
inventoryUsed = events[-1][1]["status"]["inventoryUsed"]
if inventoryUsed >= 33: # 硬编码,当身上物品太多时,造储物箱放东西
if chest_observation != "Chests: None\n\n": # 发现地上有储物箱,直接存物品
chests = chest_observation[8:-2].split("\n")
for chest in chests:
content = chest.split(":")[1]
if content == " Unknown items inside" or content == " Empty":
position = chest.split(":")[0]
task = f"Deposit useless items into the chest at {position}"
...
return task, context
if "chest" in events[-1][1]["inventory"]: # 如果身上有储物箱,则放置之
task = "Place a chest"
...
else: # 上述条件都不满足,就搓一个储物箱
task = "Craft 1 chest"
...
return task, context
messages = [
self.render_system_message(),
self.render_human_message(
events=events, chest_observation=chest_observation
),
]
if self.mode == "auto":
return self.propose_next_ai_task(messages=messages, max_retries=max_retries)
...
def propose_next_ai_task(self, *, messages, max_retries=5):
curriculum = self.llm(messages).content # 调用 LLM
...
try:
response = self.parse_ai_message(curriculum) # 尝试从结果中提取任务描述
...
context = self.get_task_context(response["next_task"]) # LLM 给出任务的解决方案
...
return response["next_task"], context
except Exception as e:
...
return self.propose_next_ai_task(
messages=messages,
max_retries=max_retries - 1,
)
def get_task_context(self, task):
# if include ore in question, gpt will try to use tool with skill touch enhancement to mine
question = (
f"How to {task.replace('_', ' ').replace(' ore', '').replace(' ores', '').replace('.', '').strip().lower()}"
f" in Minecraft?"
)
if question in self.qa_cache:
answer = self.qa_cache[question]
else:
answer = self.run_qa_step2_answer_questions(question=question)
...
context = f"Question: {question}\n{answer}"
return context
render_system_message: 定义人设- curriculum.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/curriculum.txt
- 一个有帮助的助手,目的是告诉我下个任务是什么;终极目标是尽可能多地探索、尽可能多样地完成任务。
- curriculum.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/curriculum.txt
render_human_message: 设计提问信息- 首先从插件获取角色信息、周边环境的信息备用
- 15 个 iteration 后,激活追加提问,最多 5 次
- warmup 机制
- 对于每一类环境信息,都需要在经过一定 iteration 后才能稳定在提问信息中出现,在这之前按 80% 概率出现
- 目的是确保学习过程从基础技能开始逐步走向进阶、复杂的技能
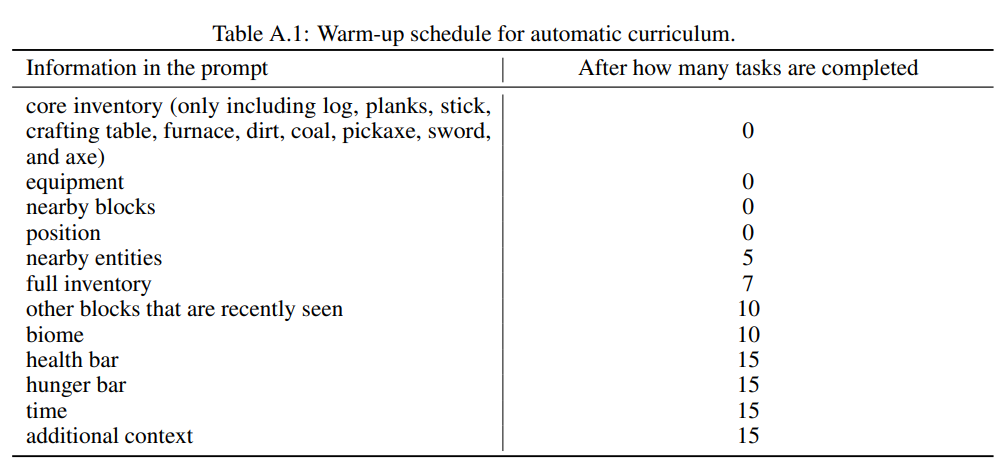
def render_human_message(self, *, events, chest_observation):
content = ""
observation = self.render_observation( # 获取角色、周边环境信息
events=events, chest_observation=chest_observation
)
if self.progress >= self.warm_up["context"]: # 15 个 iter 后进行追加提问,最多 5 次
questions, answers = self.run_qa(
events=events, chest_observation=chest_observation
)
i = 1
for question, answer in zip(questions, answers):
if "Answer: Unknown" in answer or "language model" in answer:
continue
observation["context"] += f"Question {i}: {question}\n"
observation["context"] += f"{answer}\n\n"
i += 1
if i > 5:
break
for key in self.curriculum_observations: # warmup 机制
if self.progress >= self.warm_up[key]:
if self.warm_up[key] != 0:
should_include = random.random() < 0.8
else:
should_include = True
if should_include:
content += observation[key]
...
return HumanMessage(content=content)
run_qa: 追加提问,用于扩充上下文,使用 GPT-3.5 自问自答- 先使用 LLM 提问 5~10 个问题
- curriculum_qa_step1_ask_questions.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/curriculum_qa_step1_ask_questions.txt
- 提问 5~10 次
- 必须着眼于 MC 中的一个具体概念
- 不能依赖任何上下文
- 不要问建造的问题,太难了
- curriculum_qa_step1_ask_questions.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/curriculum_qa_step1_ask_questions.txt
- 对每个新问题,到 cache (vectordb) 里去找
- 如果 miss,则调用 LLM 回答这个问题,并记录下来
- curriculum_qa_step2_answer_questions.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/curriculum_qa_step2_answer_questions.txt
- 先使用 LLM 提问 5~10 个问题
def run_qa(self, *, events, chest_observation):
questions_new, _ = self.run_qa_step1_ask_questions(
events=events, chest_observation=chest_observation
)
questions = []
answers = []
for question in questions_new:
if self.qa_cache_questions_vectordb._collection.count() > 0:
docs_and_scores = (
self.qa_cache_questions_vectordb.similarity_search_with_score(
question, k=1
)
)
if docs_and_scores and docs_and_scores[0][1] < 0.05:
...
continue
answer = self.run_qa_step2_answer_questions(question=question)
...
...
return questions, answers
Action Agent
__init__: 定义 LLM
...
from langchain.chat_models import ChatOpenAI
...
class ActionAgent:
def __init__(
self,
...
):
...
self.llm = ChatOpenAI(
model_name=model_name,
temperature=temperature,
request_timeout=request_timout,
)
render_system_message: 规定人设- action_template.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/action_template.txt
- 需要载入提前写好的 API,利用这些 API 和 Mineflayer 本身自带的接口生成 js 代码
- action_reponse_format.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/action_response_format.txt
- 定义返回代码的格式,包括对代码的解释,实现功能的每个步骤以及代码本身
- action_template.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/action_template.txt
def render_system_message(self, skills=[]):
system_template = load_prompt("action_template") # 载入 action_template.txt,说明各个接口的用法,以及规定使用方式
# FIXME: Hardcoded control_primitives
base_skills = [
"exploreUntil",
"mineBlock",
"craftItem",
"placeItem",
"smeltItem",
"killMob",
]
if not self.llm.model_name == "gpt-3.5-turbo":
base_skills += [
"useChest",
"mineflayer",
]
programs = "\n\n".join(load_control_primitives_context(base_skills) + skills) # 载入 API 代码
response_format = load_prompt("action_response_format") # 载入 action_response_format.txt,规定回复方式
system_message_prompt = SystemMessagePromptTemplate.from_template(
system_template
)
system_message = system_message_prompt.format(
programs=programs, response_format=response_format
)
assert isinstance(system_message, SystemMessage)
return system_message
render_human_message: 从游戏中获取角色自身和附近信息、上下文等summarize_chatlog: 手动匹配上轮代码运行结果中的问题
def summarize_chatlog(self, events):
def filter_item(message: str):
craft_pattern = r"I cannot make \w+ because I need: (.*)"
craft_pattern2 = (
r"I cannot make \w+ because there is no crafting table nearby"
)
mine_pattern = r"I need at least a (.*) to mine \w+!"
if re.match(craft_pattern, message):
return re.match(craft_pattern, message).groups()[0]
elif re.match(craft_pattern2, message):
return "a nearby crafting table"
elif re.match(mine_pattern, message):
return re.match(mine_pattern, message).groups()[0]
else:
return ""
chatlog = set()
for event_type, event in events:
if event_type == "onChat":
item = filter_item(event["onChat"])
if item:
chatlog.add(item)
return "I also need " + ", ".join(chatlog) + "." if chatlog else ""
Critic Agent
render_system_message: 规定人设- critic.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/critic.txt
- 判断是否达成任务目标,返回 JSON 格式的字符串
- critic.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/critic.txt
render_human_message: 总结角色信息,上下文等,与 Action Agent 的实现类似check_task_success: 判断任务是否完成
def ai_check_task_success(self, messages, max_retries=5):
...
critic = self.llm(messages).content
print(f"\033[31m****Critic Agent ai message****\n{critic}\033[0m")
try:
response = fix_and_parse_json(critic) # 解析 LLM 返回的 json 数据
assert response["success"] in [True, False]
if "critique" not in response:
response["critique"] = ""
return response["success"], response["critique"]
except Exception as e:
print(f"\033[31mError parsing critic response: {e} Trying again!\033[0m")
return self.ai_check_task_success(
messages=messages,
max_retries=max_retries - 1,
)
def check_task_success(
self, *, events, task, context, chest_observation, max_retries=5
):
human_message = self.render_human_message(
events=events,
task=task,
context=context,
chest_observation=chest_observation,
)
messages = [
self.render_system_message(),
human_message,
]
if self.mode == "manual":
return self.human_check_task_success() # 人手动判断
elif self.mode == "auto":
return self.ai_check_task_success( # LLM 判断
messages=messages, max_retries=max_retries
)
else:
raise ValueError(f"Invalid critic agent mode: {self.mode}")
Skill Manager
__init__: 定义 LLM & vectordb
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
class SkillManager:
def __init__(
self,
...
):
self.llm = ChatOpenAI(
model_name=model_name,
temperature=temperature,
request_timeout=request_timout,
)
...
self.vectordb = Chroma(
collection_name="skill_vectordb",
embedding_function=OpenAIEmbeddings(),
persist_directory=f"{ckpt_dir}/skill/vectordb",
)
...
add_new_skill: 添加新技能- 先试用 LLM 生成技能说明
- 再检查 vectordb 中是否已经有该技能
- 如果有,则更新技能代码
- 存储技能描述至 vectordb,内存中记录技能代码
def add_new_skill(self, info):
...
skill_description = self.generate_skill_description(program_name, program_code) # 生成技能描述
...
if program_name in self.skills: # 更新技能代码
...
self.vectordb._collection.delete(ids=[program_name])
i = 2
while f"{program_name}V{i}.js" in os.listdir(f"{self.ckpt_dir}/skill/code"):
i += 1
dumped_program_name = f"{program_name}V{i}"
else:
dumped_program_name = program_name
self.vectordb.add_texts( # 将技能描述添加至 vectordb
texts=[skill_description],
ids=[program_name],
metadatas=[{"name": program_name}],
)
self.skills[program_name] = {
"code": program_code,
"description": skill_description,
}
...
self.vectordb.persist() # 确认 embedding 被写入磁盘
generate_skill_description: 生成技能说明skill.txt: https://github.com/MineDojo/Voyager/blob/01fb04666a8f3ba47dec74fb4cfd46e0125fe5a0/voyager/prompts/skill.txt- 在技能说明中不要提及函数名、util 函数,尝试在 6 句话以内总结等
def generate_skill_description(self, program_name, program_code):
messages = [
SystemMessage(content=load_prompt("skill")),
HumanMessage(
content=program_code
+ "\n\n"
+ f"The main function is `{program_name}`."
),
]
skill_description = f" // { self.llm(messages).content}"
return f"async function {program_name}(bot) {{\n{skill_description}\n}}"
retrieve_skills: 检索技能
def retrieve_skills(self, query):
k = min(self.vectordb._collection.count(), self.retrieval_top_k)
if k == 0:
return []
...
docs_and_scores = self.vectordb.similarity_search_with_score(query, k=k) # 根据描述查询 vectordb 中类似的技能
...
skills = []
for doc, _ in docs_and_scores: # 根据描述查询功能代码,返回
skills.append(self.skills[doc.metadata["name"]]["code"])
return skills
运行实例日志
采样 from iteration 11
- 主循环
learn: Curriculum Agentpropose_next_task- Curriculum Agent human message:
render_human_message - Curriculum Agent ai message:
propose_next_ai_task
- Curriculum Agent human message:
****Curriculum Agent human message****
Nearby blocks: stone, gravel, coal_ore, dirt, grass_block, lapis_ore, copper_ore, andesite
Nearby entities: chicken
Position: x=84.7, y=60.0, z=258.5
Equipment: [None, None, None, None, 'wooden_pickaxe', None]
Inventory (7/36): {'crafting_table': 1, 'wooden_pickaxe': 1, 'jungle_log': 3, 'stick': 2, 'jungle_planks': 3, 'cobblestone': 3, 'dirt': 4}
Chests: None
Completed tasks so far: Mine 1 wood log, Craft a crafting table, Craft 4 wooden planks, Craft a wooden pickaxe, Mine 3 cobblestone
Failed tasks that are too hard: None
****Curriculum Agent ai message****
Reasoning: You have enough cobblestone to upgrade your pickaxe, which will allow you to mine more diverse blocks like lapis ore and copper ore.
Task: Craft a stone pickaxe.
Curriculum Agent Question: How to craft a stone pickaxe in Minecraft?
Curriculum Agent Answer: To craft a stone pickaxe in Minecraft, you will need three pieces of cobblestone and two sticks. Arrange the cobblestone in a "V" shape in the top row of the crafting table, and place the two sticks in a vertical line in the middle row. This will create a stone pickaxe.
- 主循环
rollout/reset: Skill Managerretrieve_skills
Skill Manager retrieving for 5 skills
Skill Manager retrieved skills: craftWoodenPickaxe, mineCobblestone, craftCraftingTable, craftWoodenPlanks, mineWoodLog
- 主循环
rollout/reset: Action Agentrender_human_message
****Action Agent human message****
Code from the last round: No code in the first round
Execution error: No error
Chat log: None
Biome: sparse_jungle
Time: noon
Nearby blocks: stone, gravel, coal_ore, dirt, grass_block, lapis_ore, copper_ore, andesite
Nearby entities (nearest to farthest): chicken
Health: 20.0/20
Hunger: 20.0/20
Position: x=84.7, y=60.0, z=258.5
Equipment: [None, None, None, None, 'wooden_pickaxe', None]
Inventory (7/36): {'crafting_table': 1, 'wooden_pickaxe': 1, 'jungle_log': 3, 'stick': 2, 'jungle_planks': 3, 'cobblestone': 3, 'dirt': 4}
Chests: None
Task: Craft a stone pickaxe
Context: Question: How to craft a stone pickaxe in Minecraft?
Answer: To craft a stone pickaxe in Minecraft, you will need three pieces of cobblestone and two sticks. Arrange the cobblestone in a "V" shape in the top row of the crafting table, and place the two sticks in a vertical line in the middle row. This will create a stone pickaxe.
Critique: None
- 主循环
rollout/step: Action Agent LLM 生成代码
****Action Agent ai message****
Explain: No explanation needed as there are no errors or issues in the given information.
Plan:
1) Check if there are enough cobblestone and sticks in the inventory.
2) If there are enough cobblestone and sticks, place the crafting table.
3) Craft a stone pickaxe using the cobblestone and sticks.
4) Notify the completion of the task.
Code:
async function craftStonePickaxe(bot) {
// Check if there are enough cobblestone and sticks in the inventory
const cobblestoneNeeded = 3;
const sticksNeeded = 2;
const cobblestone = bot.inventory.findInventoryItem(mcData.itemsByName.cobblestone.id);
const sticks = bot.inventory.findInventoryItem(mcData.itemsByName.stick.id);
if (cobblestone && cobblestone.count >= cobblestoneNeeded && sticks && sticks.count >= sticksNeeded) {
// Place the crafting table
const craftingTablePosition = bot.entity.position.offset(1, 0, 0);
await placeItem(bot, "crafting_table", craftingTablePosition);
// Craft a stone pickaxe using the cobblestone and sticks
await craftItem(bot, "stone_pickaxe", 1);
bot.chat("Stone pickaxe crafted.");
} else {
bot.chat("Not enough cobblestone or sticks to craft a stone pickaxe.");
}
}
- 主循环
rollout/step: Critic Agentcheck_task_success- Critic Agent human message:
render_human_message - Critic Agent ai message:
ai_check_task_success
- Critic Agent human message:
****Critic Agent human message****
Biome: sparse_jungle
Time: noon
Nearby blocks: stone, gravel, coal_ore, dirt, grass_block, lapis_ore, crafting_table, copper_ore, andesite
Health: 20.0/20
Hunger: 20.0/20
Position: x=84.7, y=60.0, z=258.5
Equipment: [None, None, None, None, None, None]
Inventory (6/36): {'stone_pickaxe': 1, 'wooden_pickaxe': 1, 'jungle_log': 3, 'cobblestone': 1, 'jungle_planks': 3, 'dirt': 4}
Chests: None
Task: Craft a stone pickaxe
Context: Question: How to craft a stone pickaxe in Minecraft?
Answer: To craft a stone pickaxe in Minecraft, you will need three pieces of cobblestone and two sticks. Arrange the cobblestone in a "V" shape in the top row of the crafting table, and place the two sticks in a vertical line in the middle row. This will create a stone pickaxe.
****Critic Agent ai message****
{
"reasoning": "You have a stone pickaxe in your inventory, which means you successfully crafted it.",
"success": true,
"critique": ""
}
- 主循环
rollout/step: Skill Managerretrieve_skills
Skill Manager retrieving for 5 skills
Skill Manager retrieved skills: craftWoodenPickaxe, mineCobblestone, craftCraftingTable, craftWoodenPlanks, mineWoodLog
- 主循环
learn: Skill Manageradd_new_skill
Skill Manager generated description for craftStonePickaxe:
async function craftStonePickaxe(bot) {
// The function is about crafting a stone pickaxe using cobblestone and sticks. It checks if there are enough cobblestone and sticks in the inventory. If there are, it places a crafting table and crafts a stone pickaxe. If there aren't enough materials, it sends a message to the chat.
}